






NotebookLMやDifyを入れて
「これで資料探しも、要約も、回答作成もかなりラクになるはず」
と期待した人は多いと思います。
でも現実はどうか。
- 古いデータを拾ってくる
- 欲しい資料が出てこない
- 似たようなファイルばかり候補に出る
- 結局、人間が探して確認し直す
……これ、あるあるですよね。
このとき、多くの人はまずAIの性能やプロンプトの書き方を疑います。
でも、実務で先に見直すべきなのは、そこではありません。
本当の原因は、ドライブの中にある“雑なファイル名”と“あいまいな版管理”です。
AIに仕事を任せたいなら、先に人間側が
AIが迷わない環境
を作る必要があります。
2026年の実務で問われるのは、単なる整理整頓ではありません。
必要なのは、機械が読める形で情報を管理することです。
まず結論。AI活用で先に直すべきなのは「プロンプト」ではなく「ファイル名」
AIが迷うのは、頭が悪いからではありません。
判断材料が雑だからです。
たとえば、こんなファイルが並んでいたらどうでしょう。
- 見積書_最終.xlsx
- 見積書_最終修正版.xlsx
- 見積書_最終修正版_確定.xlsx
人間でも「で、結局どれが本物?」となります。
だったら、AIが迷うのも当然です。
ここで必要なのは、
「AIがうまく推測してくれるはず」と期待することではありません。
一発で特定できる“唯一の正解”を、最初から用意しておくこと。
これが、AI活用の土台です。
「最終」という命名が危ない理由

「最終」「確定」「コピー」
こうした言葉は、仕事の現場ではつい使ってしまいがちです。
でも、これらはよく見ると、ファイルの中身を説明していません。
表しているのは
- そのときの気分
- 作業途中の感覚
- “たぶんこれが正しい”という空気感
だけです。
つまり、識別子ではなく、感情ラベルなんです。
ファイル名に本当に必要なのは、次の情報です。
- いつのファイルか
- どの案件・部署のものか
- 何の文書か
- 何版か
ここが入っていないと、毎回ファイルを開いて確認することになります。
人間でも面倒なのに、AI活用まで乗せると、一気に精度が落ちやすくなります。
AI活用で大事なのは「Single Source of Truth」
少しだけ難しい言葉を使うと、ここで必要なのは
Single Source of Truth
です。
つまり、「今の正解はこれです」と言い切れる1つの情報源を作ること。
AIにとってつらいのは、情報が少ないことだけではありません。
似たような候補が複数あることも、かなり厄介です。
最新版と旧版が同じような名前で並んでいる。
しかも両方とも検索対象に入っている。
これでは、新旧が混ざりやすくなります。
だから必要なのは、
AIに“推理”させないこと
です。
AIに仕事をさせたいなら
まず人間が迷いようのない状態を作っておく。
ここがスタートです。

2026年式:マシン・リーダブルな命名ルール

では、実際にどう付ければいいのか。
おすすめはシンプルです。
基本形
YYYYMMDD_案件名_種別_v01
たとえばこんな感じです。
20260403_A社_見積書_v03.xlsx20260403_営業会議_議事録_v02.docx20260403_AI活用PJ_提案資料_v01.pptx
これなら、一覧を見ただけでかなり判断しやすくなります。
① 日付は「YYYYMMDD」で固定する
ファイル名の日付は、年→月→日の順に固定するのが基本です。
おすすめは、YYYYMMDD
の形です。
例:
2026040320260512
この形のメリットは大きいです。
- 一覧表示で時系列に並びやすい
- 自分ルールの日付混在を防げる
- 記号が少なくて扱いやすい
- パス長を少しでも節約できる
逆に、こんな混在は避けたいところです。
- 260403
- R8.4.3
- 2026-04-03
- 20260403
1つのフォルダに複数の流儀が混ざると、それだけで管理コストが上がります。
ポイント
大事なのは「どれが正義か」を争うことではなく、
組織内で1つに固定することです。
② 区切り記号は「_」に寄せる
ファイル名の区切りは、できるだけシンプルにした方が安定します。
おススメは
アンダースコア(_)
です。
YYYYMMDD_案件名_種別_v01
この形にしておくと、見た目も揃いやすくなります。
逆に、次のような混在はあとで面倒です。
- 全角スペース
- 半角スペース
- かっこ
- 記号だらけの装飾
人間には読めても、運用ルールとしてはブレやすくなります。
③ 「状態」ではなく「版数」で管理する
「最新」「最終」「確定」
こうした言葉は、次の更新で意味が変わります。
だから、状態ではなく、版数で管理した方が安定します。
おすすめはこれです。
v01v02v03
例:
20260403_A社_見積書_v01.xlsx20260405_A社_見積書_v02.xlsx
この方式にすると
「修正版」
「再修正版」
「最終修正版」
みたいなカオスから抜けやすくなります。
でも、名前を直すだけでは足りない
ここ、かなり大事です。
ファイル名をきれいにしても、
旧版が検索対象に残ったままなら、AI活用はまだ不安定です。
例えば
20260401_A社_見積書_v01.xlsx20260403_A社_見積書_v02.xlsx
この2つが同じように検索対象に残っていたら、
AIはどちらも候補として見ます。
つまり、命名を整えただけでは、
“今の正解”が1つに絞られたことにはならないんです。
ここで必要になるのが、除外と削除です。
「Archiveに入れたから安心」は危ない
よくあるのがこれです。
古い版は Archive フォルダに移したから大丈夫
気持ちはわかります。
でも、それだけでは不十分なことがあります。
なぜなら、AIやRAGの取り込み設定によっては、
Archive配下も普通に検索対象に入ることがあるからです。
つまり、
- 物理的に移動した
- でも論理的にはまだ見えている
この状態が普通に起きます。
なので、古い版の扱いは
「移動したかどうか」ではなく、「AIの検索対象から外れたかどうか」
で判断した方が安全です。
古い版は「保管」「除外」「削除」で分けて考える
旧版は、なんとなく残すのではなく、次の3つに分けると整理しやすいです。
1. 不要なら削除する
もう使わない、証跡としても不要。
そういう旧版は、思い切って削除した方がスッキリします。
残しておくほど、検索候補も管理コストも増えます。
2. 残す必要があるなら保管する
監査、法務、社内ルールなどで残す必要があるものはあります。
その場合は、現役ファイルと分けて保管します。
ただし、ここで終わらないのが大事です。
3. AIの検索対象から外す
これが一番大切です。
Difyの場合
旧版文書を Disable する、または不要なら Delete する。
必要に応じて、チャンク単位でも除外します。
NotebookLMの場合
旧版ソースをノートブックから外す。
残す場合でも、少なくとも質問対象から外して扱います。
つまり、
保存していることと
AIに見せることは、別で考える
これがポイントです。
おすすめの運用は「Active / Archive」を分けること
手動で毎回判断するより、構造で管理した方がラクです。
おすすめは、最低限こう分けることです。
Active
今使う最新版だけを置く場所
Archive
旧版や保管用ファイルを置く場所
この構造にしておくと、
「現役ファイル」と「過去ファイル」が混ざりにくくなります。
ただし、さっきも書いた通り
Archiveに移しただけで安心しないこと。
AI連携しているなら、
- Archive側を同期対象にしない
- 旧版を検索対象から外す
- 必要なら削除する
ここまでセットで考えた方が安全です。
長すぎるファイル名も避けたい
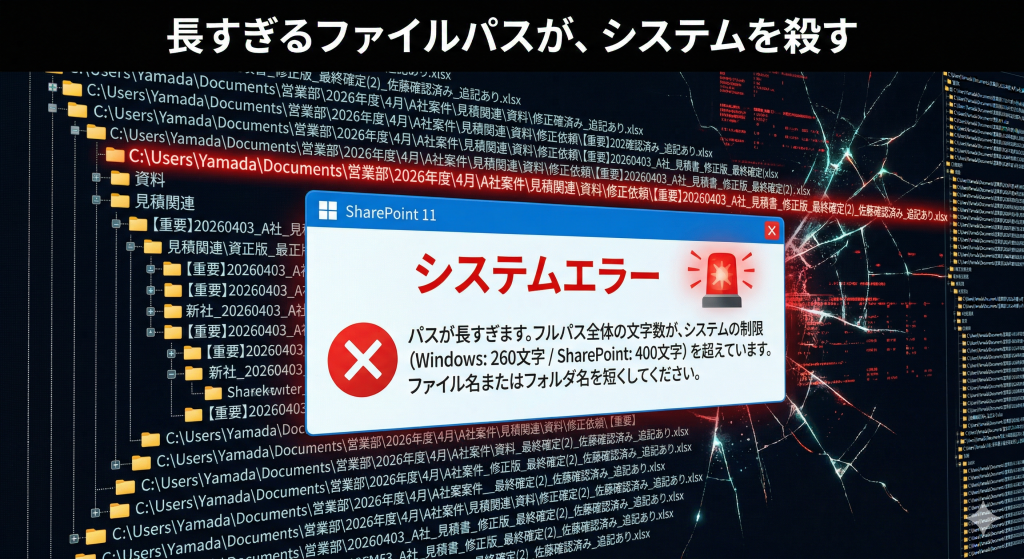
識別情報を入れようとすると、つい名前を盛りすぎてしまいます。
でも、長すぎる名前もまた扱いづらいです。
実務では、ファイル名だけでなくフォルダ階層も含めたパス長の問題があります。
深い階層と長い名前が重なると、制限に引っかかることがあります。
それ以前に、長すぎる名前は単純に読みにくいです。
なので目安としては、
- ファイル名本体は 60〜80文字程度
- 深い階層に頼りすぎない
- 案件名や部署名は略称ルールを決める
- 修飾語を増やしすぎない
このあたりを意識すると、かなり扱いやすくなります。
良いファイル名は、長い名前ではありません。
必要な情報だけで判断できる名前です。
過去の負債は、手作業で直し続けない
ここも重要です。
「これから気をつけます」だけでは、あまり変わりません。
なぜなら、すでにドライブの中に大量の旧ルールファイルがあるからです。
たとえば
- 最終.docx
- 最終の最終.xlsx
- コピー_最新版.pptx
- AI活用資料_確定版.docx
こうした過去の負債が大量に残っていると、AI導入後にずっと足を引っ張ります。
なので、実務では一括処理を考えた方が早いです。
たとえば、
- PowerToys の一括リネーム
- ChatGPTに作らせたPythonスクリプト
- 既存ルールを置換する簡単な自動処理
このあたりを使って、表記ゆれや日付形式の統一をまとめて進める方が現実的です。
1つずつ手で直すのは、正直しんどい。
その時間があるなら、AIに何を考えさせるかの設計に時間を使った方がいいです。
まず決めたい5つの基本ルール
ここだけ決めると、かなり変わります。
1. 「最終」「確定」「最新版」を使わない
曖昧語は禁止にする。
2. 日付表記を固定する
YYYYMMDD に揃える。
3. 版数を固定する
v01 v02 v03 を使う。
4. 最新版を1つにする
現役ファイルを複数並べない。
5. 古い版をAIの検索対象から外す
移動だけで終わらせず、除外や削除まで確認する。
この5つができるだけでも、AI活用の土台はかなり安定します。
ダメな例と、直した例
ダメな例
- 最終の最終のコピー.docx
- 議事録2.xlsx
- AI活用資料_最新.pptx
直した例
- 20260403_営業会議_議事録_v02.xlsx
- 20260403_AI活用PJ_提案資料_v01.pptx
- 20260403_A社_見積書_v03.xlsx
見た目の違いだけではありません。
どれをAIに見せるべきか判断しやすいかどうかが大きく変わります。
まとめ
AI導入で仕事が増える原因は、AIそのものより、
人間側のデータ管理の曖昧さにあることが多いです。
特に影響が大きいのが、この3つです。
- 雑なファイル名
- あいまいな版管理
- 旧版が検索対象に残っている状態
だから必要なのは、
- 名前を整える
- 古い版を現役の置き場から外す
- 古い版をAIの検索対象から除外または削除する
この3つをセットでやることです。
プロンプトを磨く前に、まず名前を直す。
そこを整えるだけでも、AI活用の体感はかなり変わります。
まずは自分のドライブで
「最終」「確定」「コピー」
を検索してみてください。
そこに、AI導入で仕事が増えている本当の原因が隠れているかもしれません。

